
Decomposing AI Development: A Practitioner's Guide to Navigate Decision-Making in AI System Development
There's no shortage of information on building AI solutions. But most of it lacks nuance.
I wanted to create a foundational resource for new data & AI professionals aiming to commit and gain practitioner-level knowledge over one weekend.
In this second installment, you will:
- learn how to decompose AI development into its core components
- understand the interplay between the core components
- be able to demonstrate intermediate-level knowledge in workplace discussions that will earn you respect from the AI subject matter experts on the team
If you want to master the technical foundations of AI, this is for you.
About my AI background: I've been in the trenches of AI development since 2018, way before ChatGPT made AI "cool" and table-stakes in innovation. As a Product Lead for Symbolic AI and Machine Learning based software products, I've led the development of multiple AI products from scratch. My technical expertise spans NLP, Deep Learning, KR&R, ML Lifecycle Management, and Big Data processing frameworks (like Spark), applied to solving customer problems in domains of Text Summarization, Speech, Personalization, and Large-Scale MLOps. I've made many mistakes in my AI journey, and now you don't have to.
Fair warning: This is a deep dive. And unlike my other posts, my deep dives are optimized for knowledge share, not length. This is a resource for 'builder' archetype ICs and Leaders who want to go from a surface-level understanding to a seasoned practitioner-level understanding in one weekend.
💡 I recommend committing atleast 10 hours digesting this installment.
If you're serious about mastering the fundamentals of AI development, start from part 1 of the series and work your way through to the end. Each installment builds on the last, providing you with the practical knowledge to discern reality from hype, separate fact from misinformation, and ultimately think and talk like a true AI practitioner.
Thanks to mainstream media, everyone's heard of the golden rule of AI Development: "Garbage IN, Garbage OUT".
An AI system becomes what it eats, quite literally. It lives and learns within its own data bubble. The larger and more diverse the bubble, the more 'intelligent' it gets.
The boundaries of this data bubble are rapidly expanding. While storage costs have decreased, the sheer scale of data required for sophisticated AI systems keeps overall storage expenses significant. Similarly, while processing power has become more efficient, the computational demands of advanced AI models has significantly increased typical training and operational costs. For example, OpenAI's large language model GPT-3 was trained on 45TB of text data and the cost to train it was estimated to be around $4.6 million in 2020.
As covered in Part 1 of this series, From Narrow AI to Superintelligence: What's the Difference and When Will We Get There?, the natural progression of AI's evolution is quite ambitious and we're only getting started. According to Stanford University's 2023 AI Index Report, private investment in AI reached $91.9 billion in 2022, while federal investment in AI R&D in the U.S. is set to reach $1.5 billion in 2025. These investments in AI demonstrate a strong commitment from both private and public sectors to pushing AI's potential for transformative impact.
We're on the brink of Narrow AI disrupting many industries, poised to transform how we think, work, and live in the coming decades. But:
- how does one develop an AI solution?
- what's a practical framework for approaching AI development?
- what are the key decisions to be made, and what critical trade-offs must we consider in building AI systems that meet our goals?
In this second installment, we'll answer these questions by zooming out and in, zigging and zagging to provide both the big picture and essential details.
Let's dive into the trenches.
The Three Technical Paradigms
Understanding the foundational paradigms of AI is crucial for grasping the full spectrum of AI development.
- Symbolic AI: Uses logic and knowledge representation
- Adaptive AI: Learns from data and adapts to improved performance over time
- Hybrid AI: Combines Symbolic and Adaptive approaches
Each paradigm has a set of different learning approaches that can be implemented in an AI system to help them gain new knowledge.
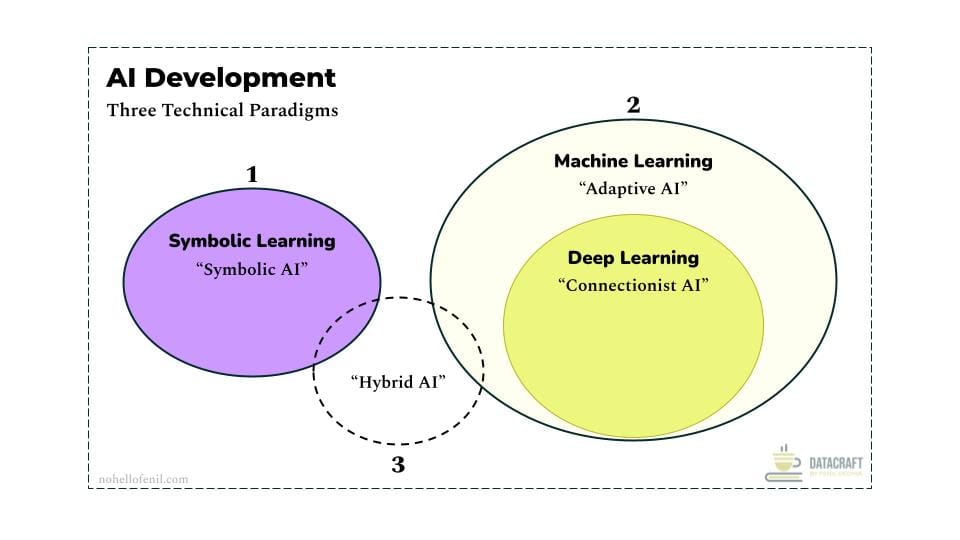
Most AI development guides jump past the basics and dive straight into specific, popular branches of AI, like the neural networks used in Deep Learning. However, the evolution of Narrow AI is progressing towards an era of Hybrid AI systems. This shift is driven by the growing importance of Explainable AI (XAI) and Ethical AI, both crucial for any hope of achieving Artificial General Intelligence (AGI).
As a Data & AI practitioner, a working knowledge of all 3 technical paradigms isn't just necessary today—it's table stakes.
Difference between Symbolic AI, Adaptive AI, and Hybrid AI
Symbolic AI, also known as Classical AI or Rule-Based AI or Good old fashioned AI (GOFAI), uses human-readable symbols and rules to represent knowledge and solve problems through logical reasoning. It relies on explicit programming of knowledge and rules, similar to how we use language or symbols in mathematics, making it particularly useful in domains where expert knowledge can be clearly codified.
This approach was the first official attempt at creating AI. It grew in popularity between the 1950s and 1980s.
- Expert systems for medical diagnosis, early Interactive Voice Response (IVR) systems, automated theorem provers, and early chess-playing programs like DeepBlue are all examples of Symbolic AI.

- Note that just the absence of adaptive learning alone is not sufficient to classify a AI system as a 'Symbolic AI' system. For example, a simple calculator operates on predefined rules and doesn't learn, but it's not considered AI. Similarly, Pac-Man isn't symbolic AI, despite its rule-based nature.
- The main identifiers of Symbolic AI are:
- Operates primarily based on predefined rules and knowledge representations
- Has explicit, human-readable rules and knowledge bases
- Has built-in capacity to explain its decision-making process, which can be accessed for troubleshooting or when deeper understanding of system's decisions or reasoning is needed
Adaptive AI (Machine Learning) is a type of AI that can learn from data and improve its performance over time without being explicitly programmed. It uses statistical techniques to find patterns in data and make decisions or predictions based on these patterns.
Under this technical paradigm, Deep Learning (or "Connectionist AI") is a specific Learning Method and Generative AI is an Application Domain. We'll understand these concepts in a little more depth in the upcoming sections.
- Image and speech recognition systems, chatbots, recommendation engines, spam filters, and predictive maintenance systems in manufacturing are a few examples of Adaptive AI.
Hybrid AI combines elements of both Symbolic AI and Adaptive AI (Machine Learning). It aims to integrate the logical reasoning and explainability of Symbolic AI with the learning capabilities and flexibility of Machine Learning.
- Self-driving cars, modern voice assistants like Siri and Alexa, humanoid robots, etc., are all good examples of Hybrid AI. They all involve ML-based systems to understand their surroundings (like recognizing objects, text, speech, etc.) and rule-based systems to make safe, predictable decisions.

Decomposing AI Development
Decomposing the AI development into a core functional framework will help us visualize both the problem space and technical implementation, making it easier to systematically track the key decisions to be made and critical trade-offs to consider in building AI systems that meet our goals.
In the following sections, we'll first digest the key components of our AI Development Framework and illustrate its application through examples in Generative AI and Natural Language Processing.
The AI Development Framework
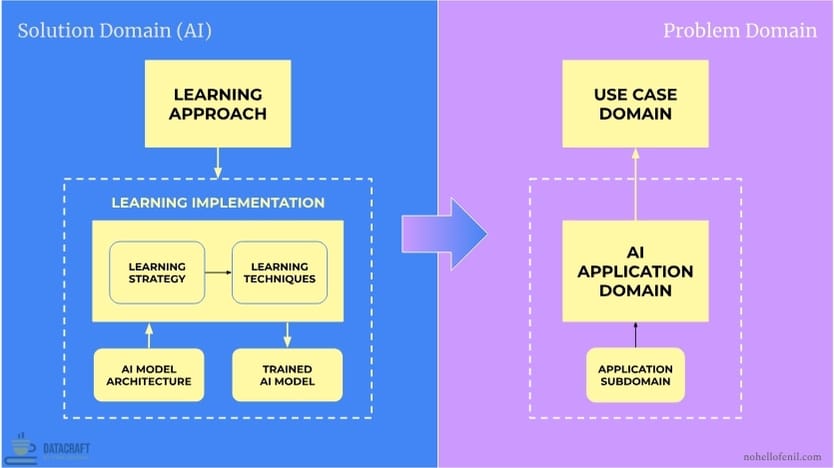
Important note: The terminology and definitions are critical to digest in leveraging this framework in the real world. The nomenclature is deliberate and carefully crafted. This is a section you might want to review multiple times to fully internalize properly.
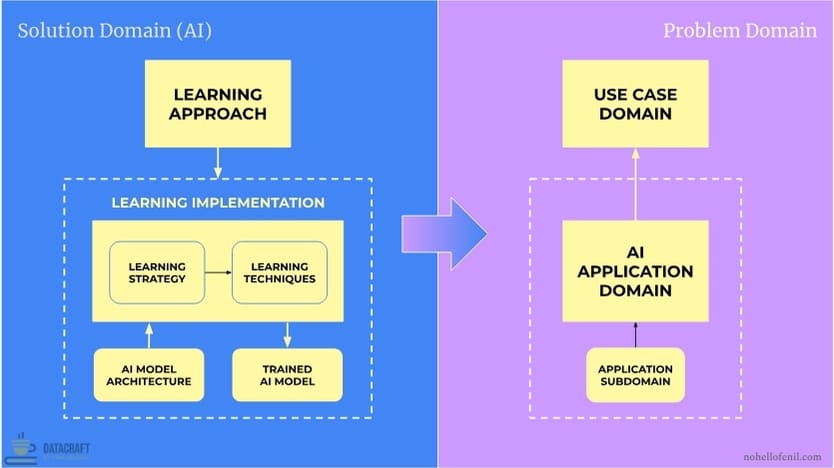
- Framework Domain
- Problem Domain: focuses on the "what" and the "why" of AI development, defining the context, requirements, and objectives.
- Solution Domain (AI): focuses on the "how" of AI development, encompassing the technical approaches, methods, and models used to create an AI solution that addresses the Problem Domain.
- Learning Approach: This is the overall process or structure of "how" the learning happens. The learning approach answers the fundamental question: How will the AI system learn from the available data?
- Learning Implementation: The process of implementing the learning approach to develop a tailored AI solution for a particular application domain or use case domain
- Learning Strategy: The specific methodology or strategy chosen to implement the Learning Approach
- Learning Techniques: The specific techniques or algorithms used to execute the Learning Strategy
- AI Model Architecture: The architectural blueprint of "how" an AI model processes data to learn, aka the model architecture "type"
- Trained AI Model: The outcome of applying learning strategies and techniques to an AI model architecture, resulting in a model that is fine-tuned for a specific application domain or use case domain.
- Application Domain (AI): The specialized areas within AI that drive the development of new AI models. It represents both broad AI fields such as Generative AI, NLP, Autonomous Systems, Explainable AI (XAI), and others
- Use Case Domain: The real-world problems to which AI solutions are applied. It represents the concrete application of AI — the specific scenarios, tasks, or problems. Use Case Domains are generally industry-agnostic, but can be industry-specific when unique tasks or problems warrant an AI solution
High-level Process and Key Relationships
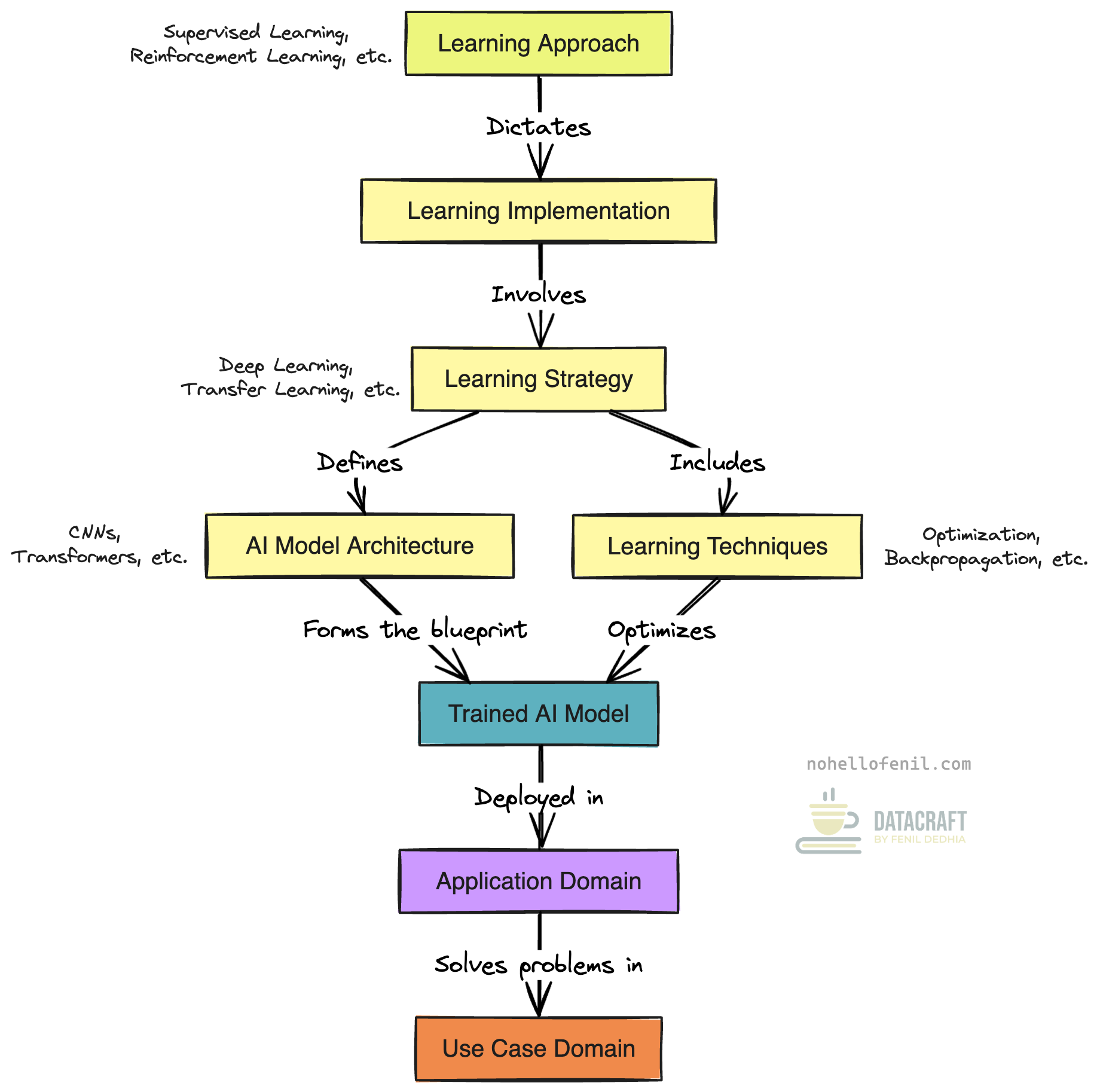
- The Learning Approach, such as supervised or unsupervised learning, dictates how learning will be executed through Learning Implementation and is the first decision to make in the AI development process.
- After selecting the Learning Approach, Learning Implementation begins, involving the selection of the Learning Strategy, Learning Techniques, and AI Model Architecture to create a tailored AI solution.
- The Learning Strategy is chosen to align with the Learning Approach and the target application domain or use case domain, defining which strategy or methodology, such as deep learning or transfer learning, will be used to optimize the learning process.
- As part of the Learning Strategy, the AI Model Architecture, such as CNNs or Transformers, is selected based on the type of available data and target task, serving as the blueprint for how the model processes data.
- Once the Learning Strategy and AI Model Architecture are in place, Learning Techniques, including optimization algorithms or backpropagation, are applied to train and fine-tune the model.
- The result of the Learning Implementation process is the Trained AI Model, a model that has been optimized using the chosen strategies, techniques, and architecture, and is now tailored to the Application Domain and Use Case Domain.
- The Trained AI Model is then deployed within a specific Application Domain, such as NLP or Computer Vision, to address broader AI fields relevant to the problem at hand.
- Finally, the Trained AI Model, by itself or part of a larger AI solution, is applied to real-world Use Case Domains, solving specific problems like medical diagnosis assistance, or code generation.
The Problem Domain
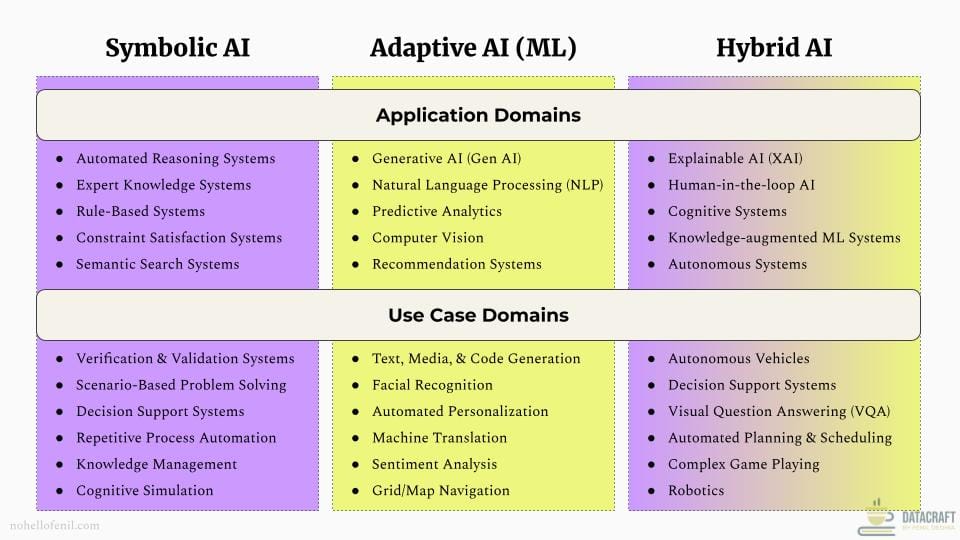
In the diagram above, I've put together common AI application domains and use case domains for which the AI solutions are developed. This is illustrative and represents a subset, not meant to be exhaustive.
Application domains represent broad AI fields, while use case domains are specific real-world problems where AI is applied. For example, NLP is an AI application domain comprising of subdomains like Natural Language Understanding (NLU) and Natural Language Generation (NLG) that are applied towards addressing specific scenarios, tasks, or problems within the use case domains of Machine Translation, Sentiment Analysis, Named Entity Resolution (NER), Text Summarization, and Text Generation.
It's important to note that techniques and systems from one application domain can be leveraged by another. For instance, the Generative AI domain often uses NLP techniques and systems, particularly Transformer-based models like Large Language Models (LLMs). This allows Generative AI solutions to handle a wide range of tasks including text, media, and code generation.
The AI solution being developed will depend on the target customer problems and use cases. Often, it will combine strengths from multiple application domains to address problem statements that span several use case domains.
Modern AI solutions rarely operate in isolation.
Take the example of Tesla's autonomous driving system. It combines image recognition to spot road signs and obstacles, sensor processing to understand the car's environment, natural language processing for driver interactions, and reinforcement learning for making split-second driving decisions.
Or consider ChatGPT: while often labeled as just a large language model, it actually demonstrates how Generative AI leverages core NLP capabilities while extending into creative writing, coding, and logical reasoning domains. Each capability strengthens the others, creating a more versatile tool.
This cross-domain approach allows for more comprehensive and versatile AI solutions. It enables AI solutions to tackle complex, real-world problems that single-domain approaches couldn't handle effectively.
The Solution Domain
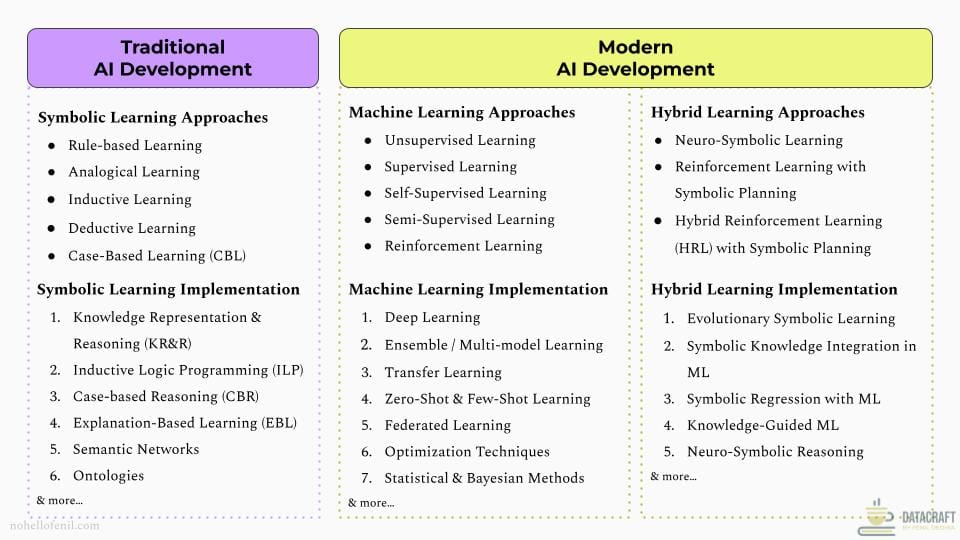
In the diagram above, I've put together common learning approaches and ways of implementing it. This is illustrative and represents a subset, not meant to be exhaustive.
Please refer to the upcoming Part 3 of the series for a deeper dive. In this second installment, we'll stay at a high-level overview for now to ensure you get a good sense of what the solution domain entails before you dive deeper into them in Part 3 of the series.
Learning Approaches
Definition: A Learning Approach is the overall process or structure of "how" the learning happens. It answers the fundamental question: How will the AI system learn from the available data?
- Symbolic AI
- Rule-based Learning creates and refines logical rules based on observed data and expert knowledge. This approach is fundamental to Symbolic AI, forming the basis for many expert systems and decision support tools. It involves encoding domain knowledge into a set of if-then rules, which the system then uses to make decisions or inferences. Rule-based learning can be highly transparent and explainable, as the decision-making process follows clear logical steps. However, it can become complex and difficult to maintain for large-scale problems with many interacting rules
- Analogical Learning solves new problems by drawing parallels with previously solved, similar problems
- Inductive Learning generalizes patterns from specific examples to form broader rules or concepts. While Inductive Learning itself is broader and could be part of both Symbolic AI and Machine Learning, it relies on logical representations and reasoning, which are core to symbolic AI, not ML.
- Deductive Learning applies general rules to specific instances to derive logical conclusions
- Case-Based Learning (CBL) solves new problems by recalling and adapting solutions from similar past cases
- Adaptive AI
- Supervised Learning uses labeled data to train models that can make predictions or decisions
- Unsupervised Learning discovers patterns in data without explicit labels
- Reinforcement Learning (RL) trains agents to make sequences of decisions in an environment to maximize a reward
- Semi-Supervised Learning combines a small amount of labeled data with a large amount of unlabeled data during training
- Self-Supervised Learning generates its own labels from raw input data, enabling models to learn meaningful representations from large amounts of unlabeled data. This approach has been revolutionary in areas like natural language processing (e.g., BERT, GPT models) and computer vision. It allows models to leverage vast amounts of unlabeled data, which is often more abundant and easier to obtain than labeled data. It reduces the need for large labeled datasets, which can be expensive and time-consuming to create. It often leads to more robust and generalizable representations, as the model learns from a wider range of data. It can serve as a powerful pre-training step before fine-tuning on specific supervised tasks
- Hybrid AI
- Reinforcement Learning with Symbolic Planning integrates RL techniques with high-level symbolic planning to improve decision-making in complex environments
- Hybrid Reinforcement Learning (HRL) with Symbolic Planning extends traditional reinforcement learning by incorporating symbolic knowledge and planning strategies to guide the learning process and improve sample efficiency
- Neuro-Symbolic Learning combines neural networks with symbolic reasoning to leverage the strengths of both approaches. This method integrates the pattern recognition and learning capabilities of neural networks with the logical reasoning and interpretability (explainability) of symbolic systems. It aims to create AI systems that can learn from data, reason about abstract concepts, and provide explainable decisions. Neuro-symbolic learning has shown promise in areas requiring both data-driven learning and high-level reasoning, such as natural language understanding, visual question answering, and complex problem-solving tasks. It addresses some limitations of pure neural or pure symbolic approaches by enabling systems to handle both structured knowledge and unstructured data effectively. IMO, this approach is going to be the cornerstone of most AI systems in the future
Learning Strategies
Definition: A Learning Strategy is the specific methodology or strategy chosen to implement the Learning Approach.

- Symbolic AI
- Knowledge Representation & Reasoning (KR&R) formalizes information about the world in a form that a computer system can utilize to solve complex tasks. It's the foundation of many symbolic AI systems, providing a structured way to represent knowledge and perform logical inference. KR&R typically uses formal languages or ontologies to represent concepts, relationships, and rules. This method enables AI systems to reason about complex scenarios, make logical deductions, and explain their decision-making process. It's particularly valuable in domains requiring transparent decision-making or where expert knowledge needs to be encoded explicitly, such as legal reasoning systems or medical diagnosis tools.
- Inductive Logic Programming (ILP) learns logical rules from examples, combining inductive learning with logic programming
- Case-based Reasoning (CBR) solves new problems by retrieving and adapting solutions from similar past cases
- Explanation-Based Learning (EBL) improves problem-solving performance by analyzing and generalizing from specific examples
- Adaptive AI
- Deep Learning uses multi-layered neural networks to learn hierarchical representations of data. This method has revolutionized machine learning, enabling breakthroughs in areas like computer vision, natural language processing, and speech recognition. Deep learning models can automatically learn features from raw data, reducing the need for manual feature engineering. Architectures like Convolutional Neural Networks (CNNs) for image processing, Recurrent Neural Networks (RNNs) for sequential data, and Transformer models for language tasks have shown remarkable performance. Deep learning's ability to handle large-scale, complex data has made it the go-to method for many modern AI applications, from autonomous vehicles to AI-powered medical imaging analysis.
- Ensemble Learning / Multi-model Learning combines predictions from multiple models to improve overall performance and robustness
- Transfer Learning applies knowledge gained from one task to improve learning in a related task
- Zero-Shot & Few-Shot Learning enables models to perform well on new tasks with very little or no specific training data
- Federated Learning trains models across decentralized devices or servers holding local data samples
- Hybrid AI
- Neuro-Symbolic Reasoning builds upon the principles of Neuro-Symbolic Learning explained earlier, focusing on the practical implementation of integrating neural networks with symbolic reasoning systems. This method emphasizes the development of inference mechanisms that can operate over both learned representations and symbolic knowledge. While Neuro-Symbolic Learning provides the foundational approach, Neuro-Symbolic Reasoning extends this by developing specific techniques for combining neural and symbolic computations during the inference process. This can involve using neural networks to ground symbolic representations in perceptual data or using symbolic knowledge to guide neural network decision-making in real-time. By doing so, it aims to create AI systems that not only learn effectively from data but can also apply logical reasoning to make more informed and explainable decisions in complex scenarios.
- Evolutionary Symbolic Learning uses genetic algorithms to evolve symbolic rules or programs
- Symbolic Knowledge Integration in Machine Learning incorporates pre-existing symbolic knowledge into machine learning models
- Symbolic Regression with Machine Learning combines symbolic expression search with machine learning techniques to discover mathematical models
- Knowledge-Guided Machine Learning uses domain knowledge to guide the learning process in machine learning models
Learning Techniques
Definition: The Learning Techniques represent the specific techniques or algorithms used to execute the Learning Strategy
- Symbolic AI
- Automated Reasoning techniques enable AI systems to make logical inferences and draw conclusions based on a set of axioms or rules. This is a cornerstone of symbolic AI, allowing systems to perform complex problem-solving and decision-making tasks. Automated reasoning includes techniques like theorem proving, which uses formal logic to derive new truths from existing knowledge, and constraint satisfaction, which finds solutions that meet a set of logical constraints. These techniques are crucial in applications requiring rigorous logical analysis, such as formal verification of software systems, automated proof checking in mathematics, and expert systems in domains like medical diagnosis or legal reasoning. Automated reasoning provides the logical backbone for many symbolic AI systems, enabling them to perform human-like reasoning tasks with precision and explanability.
- Ontologies provide formal representations of knowledge domains, defining concepts and their relationships
- Frames organize knowledge into structured units representing stereotypical situations or objects
- Production Rules use if-then statements to represent knowledge and guide decision-making
- ILP-based Rule Learning Techniques induce logical rules from examples and background knowledge
- Symbolic Planning Algorithms generate sequences of actions to achieve goals based on symbolic representations
- Constraint Satisfaction Techniques find solutions that satisfy a set of logical constraints
- Adaptive AI
- Attention Mechanisms allow neural networks to focus on specific parts of input data when processing sequential information. This technique has revolutionized many areas of machine learning, particularly natural language processing and computer vision. Attention enables models to weigh the importance of different input elements dynamically, leading to more efficient and effective learning. The most prominent example is the Transformer architecture, which uses self-attention to process entire sequences in parallel, capturing long-range dependencies more effectively than traditional recurrent neural networks. Attention mechanisms have enabled breakthroughs in language models (like GPT), machine translation, and image captioning, significantly improving the ability of AI systems to understand and generate complex, context-dependent information.
- Optimization Techniques (e.g., Stochastic Gradient Descent, Adam, RMSProp) adjust model parameters to minimize loss functions
- Evolutionary Algorithms evolve solutions over time by selecting best-performing candidates
- Search & Planning Algorithms find optimal solutions or action sequences in large state spaces
- Reinforcement Learning Techniques (e.g., Q-Learning, Policy Gradient Methods) enable agents to learn optimal behaviors through environment interaction
- Backpropagation efficiently computes gradients in neural networks for weight updates
- Dropout prevents overfitting by randomly deactivating neurons during training
- Gradient Clipping prevents exploding gradients by limiting their magnitudes
- Batch Normalization stabilizes learning by normalizing layer inputs across mini-batches
- Extreme Gradient Boosting (XGBoost) builds powerful predictive models by sequentially combining weak learners
- Hybrid AI
- Neural-Symbolic Integration techniques combine neural network learning with symbolic reasoning, bridging the gap between connectionist and symbolic AI approaches. These techniques aim to leverage the strengths of both paradigms: the learning and pattern recognition capabilities of neural networks, and the logical reasoning and interpretability (explainability) of symbolic systems. Methods in this category include embedding logical rules into neural architectures, using neural networks to learn symbolic representations, and developing hybrid architectures that can perform both neural processing and symbolic manipulation. Neural-symbolic integration enables AI systems to handle both structured knowledge and unstructured data, leading to more robust, interpretable, and generalizable models. This approach is particularly promising for tasks requiring both data-driven learning and high-level reasoning, such as visual question answering, natural language understanding, and complex decision-making scenarios.
- Hybrid Constraint Satisfaction Techniques combine symbolic constraint solving with neural network-based heuristics
- Differentiable Programming with Symbolic Logic integrates symbolic logic operations into differentiable neural computations
- Multi-Agent Reinforcement Learning with Symbolic Knowledge incorporates symbolic knowledge into multi-agent RL systems
- Hybrid Attention Mechanisms combine neural attention with symbolic knowledge to guide focus in processing
- Hybrid Constraint Learning learns constraints from data while incorporating symbolic domain knowledge
- Neuro-Symbolic Knowledge Graphs represent and reason over knowledge using both neural and symbolic methods
- Logic-Integrated Neural Networks embed logical rules and constraints directly into neural network architectures
AI Model Architecture
Definition: The AI Model Architecture is the architectural blueprint of "how" an AI model processes data to learn, aka the model architecture "type"
- Symbolic AI
- Knowledge Graphs represent information as a network of entities and their relationships. This architecture forms the backbone of many modern knowledge representation systems, enabling complex querying and reasoning over large-scale structured data. Knowledge graphs can capture intricate relationships and hierarchies, making them ideal for tasks requiring deep semantic understanding. They're widely used in applications like semantic search engines, recommendation systems, and question-answering systems. Types of knowledge graphs include semantic networks, which focus on conceptual relationships; taxonomies, which represent hierarchical classifications; and ontological graphs, which provide formal, domain-specific knowledge representations. The flexibility and expressiveness of knowledge graphs make them a powerful tool for organizing and reasoning over complex, interconnected information in symbolic AI systems.
- Logic-Based Models use formal logic to represent and reason about knowledge
- Theorem Provers systematically derive conclusions from a set of axioms or hypotheses
- Case Libraries store and organize past problem-solving experiences for future reference
- Generalization Models create abstract representations from specific examples
- Frame-Based Models organize knowledge into structured units representing stereotypical situations
- Rule-based Models use sets of if-then rules to make decisions and inferences
- Adaptive AI
- Transformers are a type of neural network architecture that has revolutionized natural language processing and is increasingly applied to other domains. Unlike traditional sequential models, Transformers process entire sequences of data in parallel, using self-attention mechanisms to weigh the importance of different input elements. This architecture enables the model to capture long-range dependencies more effectively, leading to state-of-the-art performance in tasks like machine translation, text generation, and even image processing. Large Language Models (LLMs) are a distinct class of Transformer-based models trained on vast amounts of text data, primarily for NLP tasks. Key examples of LLMs include BERT for bidirectional language understanding, GPT for generative text tasks, and Vision Transformers (ViT) for image classification. The scalability of Transformers has led to the development of LLMs like GPT-3, which exhibit remarkable generalization capabilities across a wide range of language tasks.

- Convolutional Neural Networks specialize in processing grid-like data, particularly images
- Recurrent Neural Networks process sequential data by maintaining an internal state
- Generative Adversarial Networks consist of generator and discriminator networks competing against each other
- Autoencoders learn efficient data codings in an unsupervised manner
- Graph Neural Networks operate on graph-structured data, learning node and edge representations
- Diffusion Models generate data by gradually denoising a signal
- Restricted Boltzmann Machines form undirected graphical models for unsupervised learning
- Boltzmann Machines are stochastic recurrent neural networks for unsupervised learning
- SVM (Support Vector Machines) find optimal hyperplanes for classification and regression
- Random Forests combine multiple decision trees for improved prediction and robustness
- Hidden Markov Models model sequences of observations as probabilistic state transitions
- Decision Trees make decisions based on a tree-like model of decisions and their consequences
- Hybrid AI
- Neuro-Symbolic Networks integrate neural networks with symbolic reasoning components to combine the strengths of both approaches. These architectures aim to bridge the gap between the pattern recognition capabilities of neural networks and the logical reasoning of symbolic systems. They typically involve mechanisms for translating between neural representations and symbolic knowledge, allowing for both data-driven learning and rule-based inference. Neuro-symbolic networks can take various forms, such as neural networks augmented with symbolic reasoning modules, or symbolic systems that use neural networks for perception or pattern matching. This hybrid approach enables AI systems to handle both structured knowledge and unstructured data, potentially leading to more robust, interpretable, and generalizable models. Neuro-symbolic networks are particularly promising for tasks that require both pattern recognition and high-level reasoning, such as visual question answering, natural language understanding, and complex problem-solving scenarios.
- Cognitive Architectures model human-like cognitive processes, integrating perception, reasoning, and learning
- Hierarchical Neural-Symbolic Systems organize knowledge and processing in layers of increasing abstraction
- Neuro-Symbolic Decision Networks combine neural networks with symbolic decision-making processes
- Hybrid Generative Models integrate symbolic constraints or knowledge into neural generative processes
Framing the Mathematical Formula of AI Development
We can represent our framework as a mathematical formula:
AI Development = f(AI Solution Domain, Problem Domain)
Further breaking it down,
- AI Solution Domain = Learning Approach ∩ Learning Implementation ∩ AI Model
- Problem Domain = AI Application Domain ∩ Use Case Domain
So, the complete (illustrative) formula could be expressed as:
AI Development =
f((Learning Approach ∩ (Learning Method ∪ Learning Technique) ∩ AI Model), (AI Application Domain ∩ Use Case Domain))
Example 1: Decomposing "Generative AI"
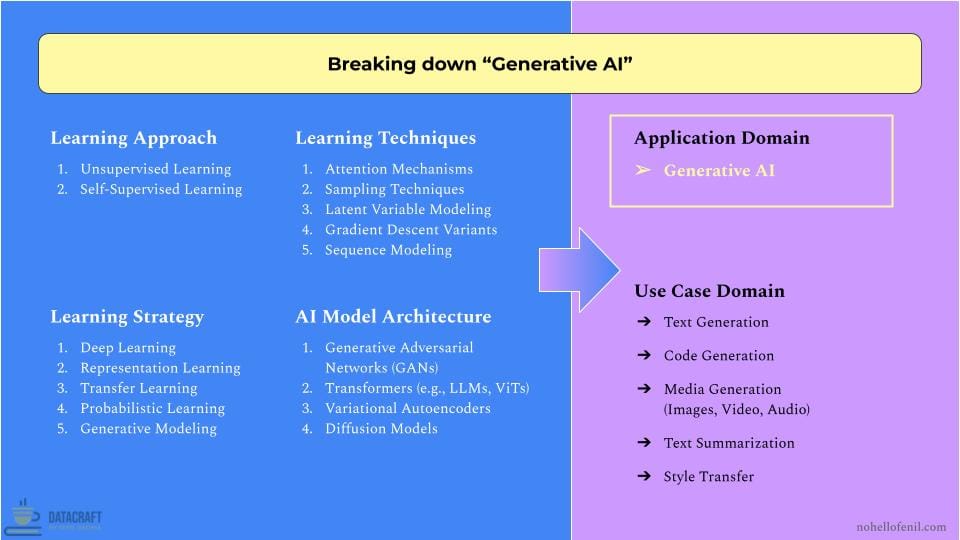
Unsupervised and Self-supervised learning approaches dominate Generative AI due to their ability to leverage vast amounts of unlabeled data, crucial for creating models that can generate diverse, high-quality outputs. These approaches allow models to discover latent patterns and representations without human-annotated labels, essential for tasks like realistic image synthesis or coherent text generation.
Transformer architectures, particularly LLMs like GPT-3 and Vision Transformers (ViTs), form the backbone of modern Generative AI. Their attention mechanisms excel at capturing long-range dependencies, enabling context-aware generation across text, code, and visual domains. For instance, DALL-E and Midjourney leverage these architectures for text-to-image generation.
Generative Adversarial Networks (GANs) and diffusion models are pivotal in media generation. GANs, like StyleGAN3, produce highly realistic images, while diffusion models (e.g., Stable Diffusion) often surpass GANs in quality and diversity, especially in tasks like image inpainting and super-resolution.
Deep learning, Representation learning, and Transfer learning strategies allow Generative AI models to capture complex patterns and generalize across tasks. This has led to multi-modal models like OpenAI's GPT-4, capable of understanding and generating both text and images.
For AI product developers, Generative AI's versatility is key. The same architectures can be applied to various use cases, from code completion (GitHub Copilot) to voice synthesis (WaveNet).
Some common challenges to expect in Gen AI development:
- Bias in training data can lead to skewed outputs.
- Massive computational resources will be required.
- Ethical considerations around synthetic content generation and potential misuse need addressing.
Balancing innovation with responsible development is the only way of creating impactful and trustworthy Generative AI products.
Example 2: Decomposing "Natural Language Processing (NLP)"
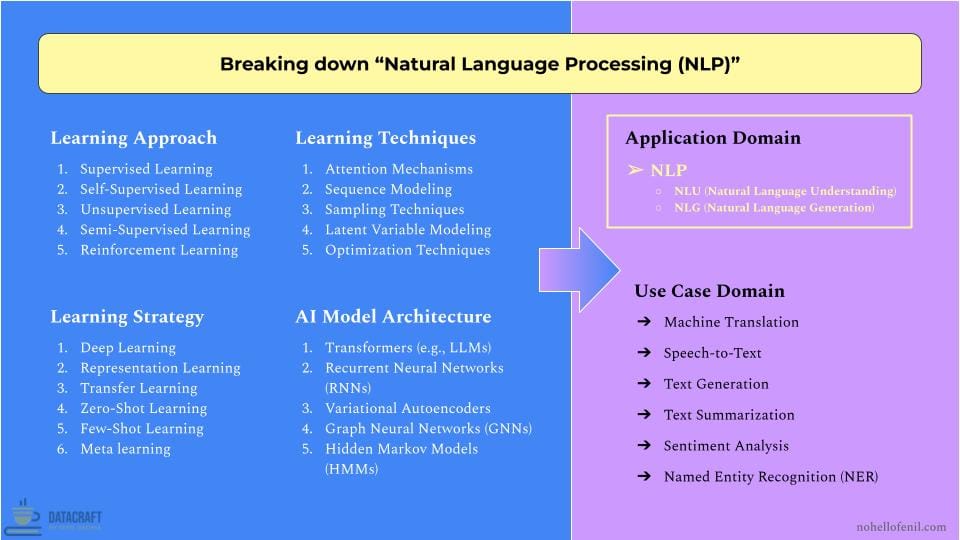
All five learning approaches are relevant to NLP, though their usage varies based on the task. Supervised, Self-Supervised, and Unsupervised learning are the most commonly used, while Semi-Supervised and Reinforcement Learning (RL) are more task-specific. In machine translation, we often lack enough paired sentences in two languages. This shortage of "labeled parallel corpora" makes it hard to train translation models using only supervised learning. Semi-supervised learning addresses this by using both paired and unpaired text data, leveraging limited labeled data alongside abundant unlabeled text to enhance translation quality. Similarly, in dialogue systems (e.g., chatbots), RL is often used to optimize conversation strategies by rewarding actions that lead to successful dialogues. RL has also been applied in text summarization and machine translation, where the model is trained to maximize specific metrics like readability or fluency.
Transformer architectures, particularly Large Language Models (LLMs) like BERT and GPT, have revolutionized NLP. Their attention mechanisms excel at capturing long-range dependencies in text, enabling breakthroughs in tasks such as machine translation and text summarization. While Transformers dominate, other architectures remain relevant. Recurrent Neural Networks (RNNs) and their variants (LSTMs, GRUs) are still used for sequential data processing. Graph Neural Networks (GNNs) show promise in tasks involving structured linguistic data, like dependency parsing.
Deep learning and transfer learning strategies have been game-changers. Pre-trained models like BERT can be fine-tuned for specific tasks, dramatically reducing the need for task-specific labeled data. This has democratized NLP, allowing smaller teams to develop sophisticated applications.
Recent advancements in few-shot and zero-shot learning are pushing the boundaries of NLP. OpenAI's latest models can perform tasks with minimal or no task-specific training, opening new possibilities for low-resource languages and specialized domains.
For AI product developers, the key is to balance model sophistication with practical constraints. While large Transformer models offer state-of-the-art performance, they may be overkill for simpler tasks where traditional methods like Hidden Markov Models can suffice. Understanding the trade-offs between model complexity, data requirements, and computational resources is crucial for developing effective and efficient NLP solutions.
For AI product developers, NLP's adaptability is a double-edged sword. While the same underlying models can be fine-tuned for diverse applications, from Amazon's sentiment analysis to IBM Watson's question-answering, the key is to balance model sophistication with practical constraints. Large Transformer models offer state-of-the-art performance but may be excessive for simpler tasks where traditional methods like Hidden Markov Models suffice. The key lies in understanding trade-offs between model complexity, data requirements, and computational resources.
Some common challenges to expect in NLP solution development:
- Language ambiguity and context-dependence complicate accurate interpretation.
- Low-resource languages lack sufficient data for robust model development.
- Ensuring privacy and security in language processing systems remains critical.
Balancing linguistic accuracy with computational efficiency is key to developing effective and accessible NLP solutions. As the field advances, addressing these challenges while maintaining ethical standards will be crucial for creating trustworthy and impactful language technologies.
Decision-Making Guide for AI Development
Use this guide to navigate the critical decisions and trade-offs in AI system development. My aim is to empower you to make informed choices based on your available data, and the target application or use case domain.

How to Use This Guide:
- Before using this guide, I suggest doing 2 things first that I've found highly productive in my AI development experience:
- Start by clearly defining the problem you're trying to solve and setting specific, measurable goals. This helps anchor all subsequent decisions to the core objectives.
- Work closely with data team to thoroughly understand your solution domain's data landscape. Assess data availability, quality, and potential biases; this will reveal constraints and opportunities that significantly enrich the discussions.
- After completing these preparatory steps, walk through each decision matrix with your AI dev team. Involve AI researchers, data scientists, engineers, and domain experts to gain diverse perspectives.
- Treat this as an iterative process. As you progress through the matrices, you may need to revisit earlier decisions based on new insights.
- Pay special attention to data and other tech constraints from data engineers and system architects. These factors are critical in shaping feasible and effective AI solutions.
- Always keep your overarching business objectives in mind. The technical decisions should support and align with these goals.
- Use this guide as a reference point, not a rigid rulebook. Be prepared to adapt your approach based on emerging challenges or opportunities. No framework or playbook in the world is going to guarantee your success without you being able to adaptable and applying common sense. Frameworks are just intuition, packaged. My golden rule for frameworks: Make the framework work for you, and make sure you don't work for the framework.
- Throughout the decision-making process, consider the ethical implications of your AI system, including fairness, transparency, and potential societal impacts. I've linked some good resources in the FAQ section's Question #6 for those handling AI ethics in their projects.
- The field of AI is rapidly evolving. Stay informed about new developments that might influence your decisions.
Let's explore how I typically approach initial decision-making in AI projects, keeping the above points in mind while adapting to the unique challenges each project presents.
Remember, this is just my approach based on my experiences. The key is to develop a process that works for your team and project, always remaining flexible and open to adjustment as you progress.
Which AI Development Paradigm to Choose?
Before diving into specific approaches and architectures, it's crucial to determine the overarching technical paradigm that best suits your problem. Each paradigm has its strengths and ideal use cases.
- Symbolic AI
- Strengths: Interpretability (explainability), reasoning with explicit knowledge, handling structured data
- Ideal for: Rule-based systems, expert systems, logical reasoning tasks
- Challenges: Difficulty in handling uncertainty, lack of adaptability to new scenarios
- Adaptive AI (Machine Learning)
- Strengths: Learning from data, handling unstructured data, adaptability
- Ideal for: Pattern recognition, prediction tasks, handling complex, high-dimensional data
- Challenges: Requires large amounts of data, potential lack of interpretability (explainability)
- Hybrid AI
- Strengths: Combines benefits of both Symbolic and Adaptive AI
- Ideal for: Complex reasoning tasks requiring both knowledge and learning from data
- Challenges: Increased system complexity, potential integration issues
Decision Matrix: Choosing the Right Paradigm
| Factor | Symbolic AI | Adaptive AI | Hybrid AI |
|---|---|---|---|
| Structured Knowledge | High | Low to Moderate | Moderate to High |
| Large Datasets | Limited | Abundant | Moderate to Abundant |
| Data Combination | Primarily structured | Primarily unstructured | Mix of structured and unstructured |
| Data Quality and Completeness | High quality, complete | Can handle noise and incompleteness | Moderate to high quality |
| Data Update Frequency | Low to moderate | High | Moderate to high |
| Problem Complexity | Well-defined, rule-based | Complex, pattern-based | Complex, requiring both rules and patterns |
| Interpretability / Explainability Needs | High | Low to Moderate | Moderate to High |
| Adaptability Requirements | Low | High | Moderate to High |
| Domain Knowledge Availability | High | Low to Moderate | Moderate to High |
Key Considerations for Paradigm Selection
- Problem nature: Is your problem domain going to benefit primarily from a rule-based or pattern-based solution?
- What type and volume of data do you have?
- Structured knowledge: Well-organized, rule-based information (e.g., databases, ontologies)
- Large datasets: High volume of data, which can be structured or unstructured
- Combination: Mix of structured knowledge and large datasets
- Quality and completeness: Consider data accuracy, consistency, and gaps
- Update frequency: How often does the data change or get updated?
- Interpretability / Explainability requirements: How important is it to understand the system's decision-making process?
- Adaptability needs: Does your system need to learn and adapt to new scenarios frequently?
- Long-term goals and solution evolution
- Example: In developing an AI assistant for customer service, starting with a purely adaptive AI approach (like a large language model) might offer quick deployment and broad capabilities. However, considering long-term goals of improved consistency and task-specific performance, evolving towards a hybrid approach that incorporates symbolic reasoning for specific tasks (e.g., following company policies, handling structured queries) could be beneficial. This allows for incremental improvement and specialization over time.
Which Learning Approach to Use?
The learning approach defines the overall process of how the AI system acquires knowledge or improves performance. The choice depends on your technical paradigm and specific problem requirements.
Step 1:
Start --> Select AI Development Paradigm
Step 2:
If chosen technical paradigm is
- Symbolic AI, proceed to 3
- If Adaptive AI, skip to 4
- If Hybrid AI, skip to 5
Step 3:
Symbolic AI Decision Matrix: Choosing the Learning Approach
| Problem Type | Learning Approach | Best For |
|---|---|---|
| Explicitly defined rules guide system behavior | Rules-based Learning | Expert systems, diagnosis tools, decision support systems |
| Solving new problems based on solutions to similar past problems | Analogical Learning | Legal reasoning, creative problem-solving, design tasks |
| Deriving general rules from specific examples | Inductive Learning | Pattern recognition, scientific discovery, predictive modeling |
| Applying general rules to reach specific conclusions | Deductive Learning | Logical inference systems, theorem proving, formal verification |
| Using specific instances to solve new problems | Case-Based Learning | Customer support systems, medical diagnosis, legal precedent analysis |
Step 4:
Adaptive AI Decision Matrix: Choosing the Learning Approach
| Data Availability | Learning Approach | Best For |
|---|---|---|
| Learning from labeled data with input-output pairs | Supervised Learning | Image classification, spam detection, sentiment analysis |
| Finding patterns in unlabeled data without predefined categories | Unsupervised Learning | Customer segmentation, anomaly detection, feature learning |
| Using both labeled and unlabeled data to improve learning | Semi-Supervised Learning | Text classification with limited labels, image recognition with partial annotations |
| Automatically generating labels from the inherent structure of data | Self-Supervised Learning | Language model pre-training, representation learning for computer vision |
| Learning through interaction with an environment to maximize rewards | Reinforcement Learning | Game playing, robotics, autonomous systems, process optimization |
Step 5:
Hybrid AI Decision Matrix: Choosing the Learning Approach
| Complexity Level | Learning Approach | Best For |
|---|---|---|
| Need to combine knowledge-based high-level reasoning with adaptive learning | Neuro-Symbolic Learning | Complex reasoning tasks, interpretable AI systems, knowledge integration in deep learning |
| Need to integrate high-level planning with low-level learning | RL with Symbolic Planning | Task and motion planning in robotics, strategic decision-making in complex environments |
| Need adaptive learning at multiple levels of abstraction | Hierarchical RL | Complex, long-horizon tasks, multi-task learning, skill acquisition in robotics |
Key Considerations for Selecting a Learning Approach
- How complex is your problem domain?
- Example: For a NLP task like chatbot development, the complex, open-ended nature of human dialogue might favor a Reinforcement Learning approach. This allows the chatbot to learn from interactions and improve its responses over time, adapting to various conversation contexts and user behaviors.
- What are your processing power and memory constraints?
- Example: In developing a real-time object detection system for autonomous drones in search and rescue operations, computational resources are limited due to the drone's small size and power constraints. While a deep learning approach like YOLOv5 might offer superior accuracy, the limited onboard processing power and memory might favor a more lightweight traditional computer vision approach using HOG (Histogram of Oriented Gradients) with SVM (Support Vector Machine). This strategy allows for faster inference times and lower power consumption, crucial for extending flight time and ensuring real-time performance, even if it means sacrificing some accuracy in complex scenarios.
- Desired outcome and performance metrics
- Example: In a financial fraud detection system, where false negatives (missing actual fraud) are much more costly than false positives, a supervised learning approach with careful consideration of class imbalance and custom loss functions might be preferred. This allows for fine-tuning the model's performance towards minimizing missed frauds, even at the cost of some false alarms.
Which Learning Strategy to Apply?
The learning strategy is the specific methodology chosen to implement the learning approach. Your choice depends on your selected paradigm, learning approach, and specific problem requirements.
Step 1:
Start --> Select AI Development Paradigm
Step 2:
If chosen technical paradigm is
- Symbolic AI, proceed to 3
- If Adaptive AI, skip to 4
- If Hybrid AI, skip to 5
Step 3:
Symbolic AI Decision Matrix: Choosing the Learning Approach
| Learning Approach | Learning Strategy | Best For |
|---|---|---|
| Rules-based, Deductive | Knowledge Representation & Reasoning (KR&R) | Complex rule-based systems, expert systems, semantic reasoning |
| Inductive | Inductive Logic Programming (ILP) | Learning logical rules from examples, relational learning |
| Case-Based | Case-based Reasoning (CBR) | Problem-solving based on past experiences, legal reasoning |
| Rules-based, Inductive | Explanation-Based Learning (EBL) | Improving problem-solving efficiency, theory refinement |
Step 4:
Adaptive AI Decision Matrix: Choosing the Learning Strategy
| Learning Approach | Learning Strategy | Best For |
|---|---|---|
| Supervised, Unsupervised | Deep Learning | Complex pattern recognition, image and speech recognition |
| Multiple approaches | Ensemble Learning | Improving model robustness, reducing overfitting |
| Supervised, Self-Supervised | Transfer Learning | Leveraging knowledge from related tasks, few-shot learning |
| Supervised, Semi-Supervised | Federated Learning | Privacy-preserving distributed learning, edge computing |
| Multiple approaches | Meta Learning | Improving the learning process itself, few-shot learning |
| Supervised, Active Learning | Bayesian Learning | Incorporating uncertainty, probabilistic modeling |
| Supervised, Reinforcement | Continual Learning | Ongoing learning without forgetting, lifelong learning systems |
Step 5:
Hybrid AI Decision Matrix: Choosing the Learning Strategy
| Learning Approach | Learning Strategy | Best For |
|---|---|---|
| Neuro-Symbolic | Neuro-Symbolic Reasoning | Combining neural networks with symbolic logic, interpretable deep learning |
| Symbolic + Adaptive | Evolutionary Symbolic Learning | Optimizing symbolic rules, adaptive expert systems |
| Multiple approaches | Knowledge-Guided Machine Learning | Incorporating domain knowledge into ML models, explainable AI |
| Multiple approaches | Multi-Paradigm Learning | Integrating multiple learning paradigms, complex problem-solving |
Key Considerations for Learning Strategy Selection
- Alignment with problem complexity and data characteristics
- Example: For a computer vision task like facial recognition, deep learning strategies (e.g., Convolutional Neural Networks) are well-suited due to their ability to handle complex, high-dimensional image data. In contrast, for a customer churn prediction problem with structured data, ensemble methods like Random Forests or Gradient Boosting might be more appropriate.
- Trade-off between model interpretability and performance
- Example: In healthcare diagnostics, a highly accurate but opaque deep learning model might not be suitable due to the need for explainable decisions. Instead, a slightly less accurate but more interpretable model (e.g., decision trees or logistic regression with feature importance) might be preferred. Conversely, in a recommendation system for an e-commerce platform, the priority on prediction accuracy might favor complex, less interpretable models like neural collaborative filtering.
- Computational resources and scalability requirements
- Example: For a startup developing a real-time fraud detection system, the choice between an online learning approach (which updates the model incrementally) and batch learning (which retrains the entire model periodically) would depend on their available computing resources and the volume of incoming data. Online learning might be preferred for its lower computational overhead and ability to adapt quickly, while batch learning could provide more stable and optimized models if resources allow for periodic retraining.
Which AI Model Architecture to Implement?
Step 1:
Choose High-Level Model Type
| Model Type | Characteristics | Best For | Examples |
|---|---|---|---|
| Linear Models | Simple, interpretable | Clear linear relationships, high interpretability needs | Linear regression, logistic regression, SVMs |
| Tree-based Models | Versatile, handle non-linear relationships | Wide range of problems, feature importance | Decision trees, random forests, gradient boosting machines |
| Neural Networks | Complex, powerful for unstructured data | Tasks with large datasets, pattern recognition in unstructured data | CNNs, RNNs, Transformers |
| Specialized Models | Designed for specific problem types | Unique problem structures or data types | KNN, Naive Bayes, Hidden Markov Models |
Examples of where the high-level model types are applied
| Model Type | Application Domain or Use Case Domain |
|---|---|
| Linear Models | Sales forecasting, risk assessment, simple classification, pricing optimization, resource allocation |
| Tree-based Models | Customer churn prediction, fraud detection, recommendation systems, credit scoring, feature importance analysis |
| Neural Networks | Image recognition, natural language processing, speech recognition, autonomous systems, complex pattern recognition |
| Specialized Models | Customer segmentation, spam detection, speech recognition, anomaly detection, time series analysis |
Step 2:
Select AI Development Paradigm
After choosing the high-level model type, proceed to select the AI paradigm:
- If chosen model type aligns with Symbolic AI, proceed to 3
- If chosen model type aligns with Adaptive AI, skip to 4
- If chosen model type suggests a Hybrid approach, skip to 5
Step 3:
Symbolic AI Decision Matrix: Choosing the Model Architecture
| Problem Characteristics | Model Architecture | Best For |
|---|---|---|
| Complex, interconnected information | Knowledge Graphs | Representing relationships, semantic reasoning |
| Formal reasoning tasks | Logic-Based Models | Mathematical proofs, automated reasoning |
| Experience-based reasoning | Case Libraries | Legal reasoning, medical diagnosis |
| Clear, explicit rules | Rule-based Models | Expert systems, decision support systems |
Step 4:
Adaptive AI Decision Matrix: Choosing the Model Architecture
| Data Type / Task | Model Architecture | Best For |
|---|---|---|
| Image, spatial data | Convolutional Neural Networks (CNNs) | Image recognition, object detection |
| Sequential, time-series data | Recurrent Neural Networks (RNNs/LSTMs/GRUs) | Natural language processing, time series forecasting |
| Text, sequential data | Transformers | Language modeling, machine translation |
| Tabular data | Tree-based Models (e.g., Random Forests) | Structured data analysis, feature importance |
| High-dimensional data | Support Vector Machines (SVMs) | Classification with clear margins |
| Probability modeling | Probabilistic Graphical Models | Bayesian inference, causal reasoning |
Step 5:
Hybrid AI Decision Matrix: Choosing the Model Architecture
| Integration Needs | Model Architecture | Best For |
|---|---|---|
| Combining neural networks with symbolic representations | Neuro-Symbolic Networks | Interpretable deep learning, knowledge integration |
| Multi-level reasoning and learning | Hierarchical Neural-Symbolic Systems | Complex task decomposition, abstract reasoning |
| Mimicking human cognitive processes | Cognitive Architectures | General AI systems, cognitive modeling |
Key Considerations for Architecture Design
- Problem complexity and data structure
- Example 1: For customer churn prediction in a telecom company, a tree-based model like Random Forest might be preferred. It can handle the mix of categorical and numerical data typical in customer datasets, capture non-linear relationships between features (e.g., usage patterns and churn likelihood), and provide feature importance rankings to guide retention strategies.
- Example 2: In a computer vision task for medical image analysis, the need to process 2D or 3D images with spatial relationships would favor Convolutional Neural Networks (CNNs). CNNs are specifically designed to capture spatial hierarchies in image data, making them ideal for tasks like tumor detection or organ segmentation in MRI or CT scans.
- Interpretability vs. performance trade-off
- Example 1: In credit scoring for loan approvals, a bank might choose a linear model like logistic regression over a more complex neural network. While the neural network might achieve slightly higher accuracy, the logistic regression model offers clear coefficients that can be easily explained to regulators and customers, showing how each factor (income, credit history, etc.) influences the credit decision.
- Example 2: For a large-scale natural language processing task, such as developing a chatbot for a global customer service platform, Transformer architectures (like BERT or GPT) would be preferred. While computationally intensive during training, Transformers offer superior parallelization capabilities and can efficiently handle long-range dependencies in text, allowing for better performance and scalability when deployed across millions of users.
- Data volume and computational resources
- Example: For a start-up developing a computer vision system for retail inventory management with limited labeled data and computing power, they might opt for a pre-trained CNN with transfer learning rather than training a large neural network from scratch. This approach leverages existing visual features learned from large datasets, requiring less data and computational resources while still providing good performance for object detection and classification in store environments.
FAQs
Answering key questions about applying the framework and using the decision-making guide in your AI development journey.
Have a question that's not covered here? Email me at fenil.h.dedhia@gmail.com – I'm happy to help!
Question #1: The AI Development framework suggests a clear separation between Application Domains like NLP and Generative AI, but modern AI systems often blur these lines. For example, GPT-4 uses NLP techniques but is considered Generative AI. How should practitioners think about these overlapping domains?
Correct – modern AI systems often transcend traditional domain boundaries. The framework's categorization isn't meant to suggest rigid separation but rather to provide a structured way to understand different aspects of AI development.
Think of Application Domains like specialized tools in a workshop. A power drill (NLP) can be used independently for drilling holes, but it might also be part of a larger project involving multiple tools (Gen AI). GPT-4 is a perfect example: it's built on transformer architectures (originally developed for NLP) but has evolved into a generative system capable of tasks well beyond traditional NLP.
The key is understanding that Application Domains represent areas of specialized expertise and techniques, while actual AI solutions often combine these domains to solve complex problems. This fundamental relationship is captured in our framework's mathematical representation:
AI Development = f((Learning Approach ∩ (Learning Method ∪ Learning Technique) ∩ AI Model), (AI Application Domain ∩ Use Case Domain))
The intersection (∩) of Application Domain with Use Case Domain in the formula explicitly recognizes that real-world AI solutions often operate at the convergence of multiple domains. This cross-domain approach allows for more comprehensive and versatile AI solutions.
For deeper insights into how modern AI systems combine different domains, I recommend reading:
- "Leveraging Multi-AI Agents for Cross-Domain Knowledge Discovery" paper
- Stanford's "Foundation Models" report
- "What is Multi-modal AI? An introduction" article
- "How Gen AI and NLP are Revolutionizing Search Technology" article
- "Merging Separate Generative AI Systems Into One Big Brainiac" article
Question #2: The AI Development Framework presents Symbolic, Adaptive, and Hybrid AI paradigms as equal options, while the industry heavily favors Adaptive AI/ML approaches. How does this framework help practitioners navigate this market reality?
Yes, the current industry landscape is heavily skewed toward Adaptive AI/ML. But there's a method to this madness.
The framework gives equal theoretical weight to all paradigms for 2 critical reasons:
- Future-proofing: The pendulum is swinging back toward hybrid approaches. Look at the growing emphasis on explainable AI and the integration of symbolic reasoning in modern systems. OpenAI's research on constitutional AI and DeepMind's work on neuro-symbolic systems suggest we're moving toward more hybrid approaches.
- Complete understanding: To build truly effective AI systems, practitioners need to understand all available tools – even if they're not currently the most popular ones. Symbolic AI's principles of explicit knowledge representation and logical reasoning are making a comeback in modern hybrid systems.
For real-world validation, look at:
- IBM's Project Debater (hybrid approach)
- DeepMind's AlphaFold (combines deep learning with symbolic knowledge of protein structures)
- Microsoft's Z3 Theorem Prover (symbolic reasoning in software verification)
The key is understanding that while Adaptive AI dominates today's applications, the future of AI development likely lies in hybrid approaches that combine the best of all paradigms.
Question #3: Your explanation of Hybrid AI suggests it's the future, but many successful AI products today use pure ML approaches. How can teams determine when simpler approaches might better serve their goals?
Let me be direct: you should absolutely use the simplest approach that solves your problem effectively. No one should immediately jump to hybrid approaches as their starting point.
You don't need a self-driving car when a bicycle will get you to your destination.
As covered in the decision-making guide, your choices need to be strategic against your data's characteristics and all the different types of constraints at play.
Many successful AI products today accomplish their goals perfectly well with pure ML approaches. The rise of hybrid approaches isn't about replacing simpler solutions – it's about addressing increasingly complex problems that pure ML struggles with, like:
- Explainability requirements in regulated industries
- Complex reasoning tasks requiring both learning and logic
- Systems needing guaranteed behavior constraints
Take GitHub Copilot as an example. While its core is a large language model (pure ML), GitHub is gradually introducing more structured elements to improve code correctness and security compliance – a shift toward hybrid approaches driven by real-world needs.
Question #4: How to leverage your decision-making guide for iterative development? Won't I need to adjust my development approach based on a Model's results and other learnings during implementation?
The framework is designed to support iterative development, understood best when seen through its functional representation:
AI Solution Domain =
f(Learning Approach ∩ (Learning Method ∪ Learning Technique) ∩ AI Model)
Each component can be revisited and refined based on:
- Model performance metrics
- New data insights
- Changing data characteristics
- Changing business requirements
- Technical constraints discovered during implementation
When performance metrics don't meet expectations, teams can systematically evaluate which components to adjust:
- Is the Learning Approach appropriate for your data quality/quantity?
- Do the insights suggest a need to pivot to a different Model Architecture?
- Do the quality of your AI model's outputs suggest a need to modify your Learning Techniques?
For practical implementation of iterative AI development, see the resources linked to the answer of Question #3, plus these ones that may be closer to answering the specific question of the iterative process in AI development:
- Databrick's Standardizing the ML Lifecycle guide
- Microsoft's Team Data Science Process
- Designing Machine Learning Systems by Chip Huyen
Disclaimer: I haven't personally vetted all these resources, but they represent commonly referenced starting points for diving deeper into iterative AI development.
Question #5: As a Product Manager, I often face business constraints, time-to-market pressures, and legacy system limitations. How can I leverage this framework to make informed trade-offs between the ideal technical approach and these practical realities?
First of all, no framework in the world survives unchanged after its first contact with business reality. Our decision-making guide for AI development (or any for that matter) should be used as a reference point, not a rigid rulebook.
Secondly, most AI projects don't start from scratch – they're often additions to existing systems. Let's be practical about navigating both business and technical constraints.
Here's my generalized recommendation:
- Start with the Integration Strategy
- Map existing constraints (data pipelines, APIs, infrastructure, time-to-market needs)
- Identify components that can be enhanced vs. replaced with AI
- Consider implementing AI features as microservices for minimal disruption
- Use the Framework to:
- Understand the full spectrum of possibilities
- Identify the minimum viable approach for your specific use case
- Plan for scalability and future enhancements
- Adapt components based on legacy constraints:
- Learning Approach: May be constrained by existing data structures
- Model Architecture: Must consider system performance limits
- Deployment Strategy: Often needs to work within established DevOps practices
For example, you might start with a simpler supervised learning approach to get to market quickly, while architecting your system to accommodate more sophisticated approaches later. Many successful AI products began this way – take GitHub Copilot, which started with basic completion features before evolving into a more comprehensive AI pair programmer.
If your legacy product is an e-commerce platform and you want to add AI-powered recommendations, you might want to start with simple collaborative filtering that works with existing user behavior data, rather than implementing a complex deep learning solution requiring architectural changes.
Note that while this framework helps you navigate technical implementation choices and business constraints, overarching governance requirements and ethical considerations operate at a different level. See Question #6 for guidance on how these considerations shape the boundaries within which you can make your technical and business decisions.
- Google's "Rules of ML" is a great read for beginners
Video introduction to Google's 'Rules of ML'
Question #6: Data governance and privacy considerations significantly impact AI development choices. How should teams incorporate these requirements when using the decision-making guide to choose between different AI development approaches?
The AI Development Framework and Decision-Making Guide presented in this second installment help you navigate technical implementation choices - how to build AI systems. They provide structured ways to evaluate key decisions (like choosing between learning approaches or model architectures) and assess critical trade-offs (like model complexity vs. interpretability, or performance vs. computational cost). Data governance and privacy considerations operate at a different, overarching level - they define the boundaries within which those technical choices must be made.
Think of it like building a house: The framework helps you decide between different construction methods and materials (brick vs. wood, open floor plan vs. traditional layout). Building codes and zoning laws, like governance requirements, don't tell you how to build - they set the rules you must follow regardless of your construction choices.
In practice, this means:
- Start with governance requirements to understand your constraints:
- Data privacy regulations you must comply with
- Security standards that must be met
- Ethical guidelines your organization follows
- Use the AI Development Framework and associated Decision-Making Guide within these boundaries to make implementation decisions:
- Choose learning approaches that can work with allowable data usage
- Select model architectures that provide required transparency
- Design system architectures that enable proper data handling
- Regularly validate that technical choices align with governance requirements:
- Assess privacy implications of selected approaches
- Verify compliance with security standards
- Evaluate ethical implications of model decisions
These considerations will be covered briefly in Part 4 of the series, but for immediate guidance, explore:
- ICML's concent on topics related to Ethical and Fair AI development
- Virtual sessions accessible here: https://icml.cc/virtual/2024/events/oral
- Papers: https://icml.cc/virtual/2024/papers.html?filter=titles
- Google's End-to-End Responsibility guide on a responsible approach to AI
- Practical Data Privacy by Katharine Jarmul
Note: While I'm reviewing these resources as I prepare Part 4, my coverage will only provide an overview. For those working on ethical and responsible AI projects, I strongly recommend studying these materials directly – they're invaluable for navigating real-world AI development challenges.
Question #7: Given how rapidly AI technology is evolving, how should teams future-proof their approach when using this framework?
This is exactly why I emphasize understanding components rather than specific implementations. The fundamentals of AI development will remain relatively stable even as implementations evolve rapidly.
Consider these principles for future-proofing:
- Focus on modular architecture that can swap components
- Build with abstraction layers between business logic and AI implementations
- Plan for model versioning and updates from the start
- Design for scalability in both data and computation
Today's cutting-edge might be tomorrow's baseline (look at how transformer architectures became common), but the underlying principles of how we decompose and approach AI development remain valuable.
For staying current with AI evolution, my recommendation would be to:
- Follow papers and discussions on arXiv
- Build a habit reading major AI lab releases and technical blogs
- Join AI practitioner communities
- If you're a developer, participate in relevant open-source projects
As a builder, your goal shouldn't be to predict the future perfectly, but to build systems flexible enough to adapt as technology evolves.
Member discussion